The Transformer Architecture is considered the “Secret Sauce” behind the success of Large Language Models. Introduced in the 2017 paper “Attention Is All You Need,” it revolutionized the field of Artificial Intelligence.
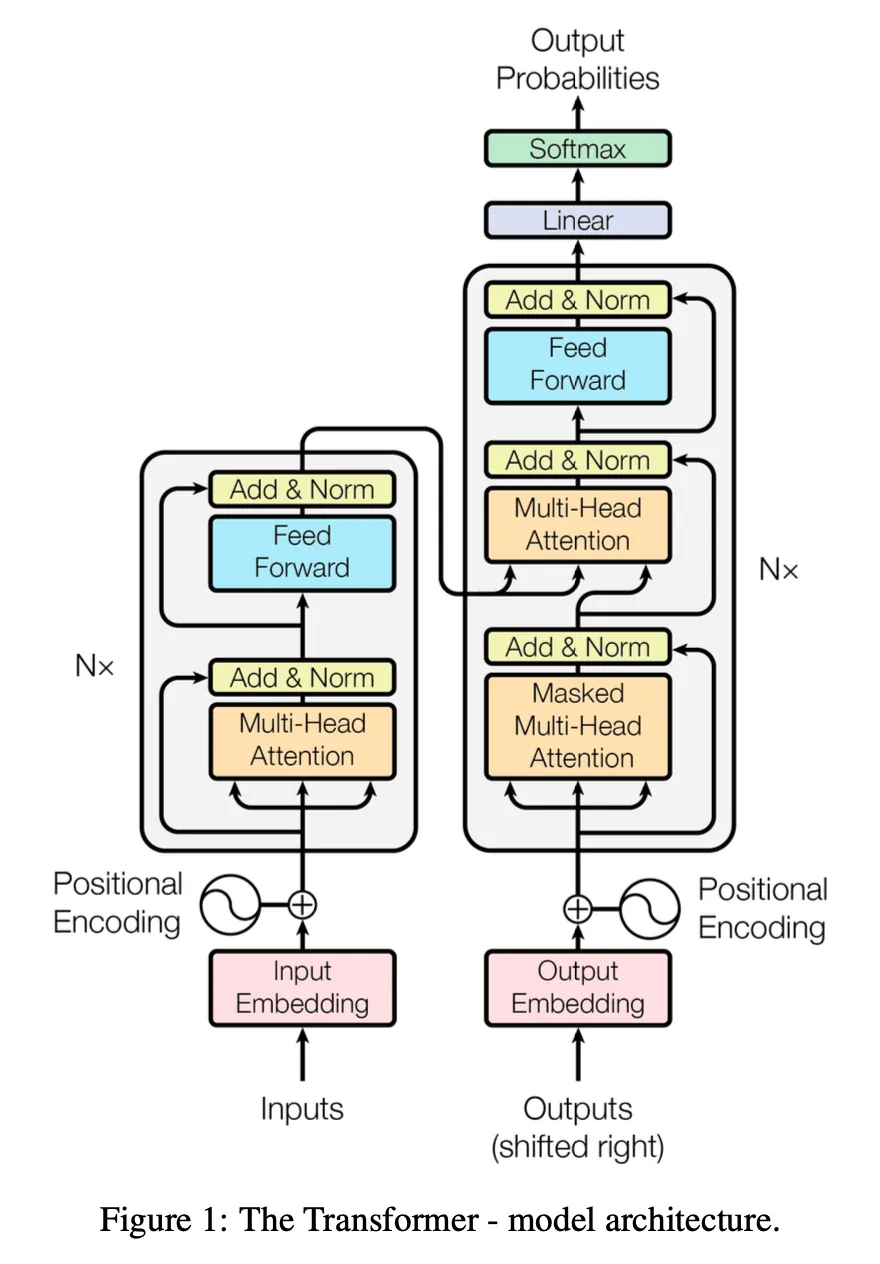
Key Components
The architecture involves several complex mechanisms including:
- Input/Output Embedding
- Positional Encoding
- Multi-Head Attention
- Feed Forward layers
- Add & Norm
Process
- Input Text: Text to be translated/processed.
- Tokenization: Breaking text into tokens and assigning IDs.
- Encoder (Transformer): Converts tokens into Vector Embeddings.
- Vector Embeddings: High-dimensional vectors capturing semantic meaning.
- Partial Output: The model uses partial output text (for translation/generation).
- Decoder (Transformer): Takes vector embeddings and partial output to predict the next word.
- Generation: Generates output one word at a time.
- Final Output: The comprehensive result.
Significance
This architecture enables models to process language with unprecedented effectiveness, leading to the rapid advancement of generative text capabilities.
